Member-only story
Reshaping a DataFrame with Pandas stack() and unstack()
7 tricks to effectively use the Pandas stack() and unstack()
Published in
5 min readMar 11, 2022

Reshaping is often needed when you work with datasets that contain variables with some kinds of sequences, say, time-series data.
Source from University of Virginia, Research Data Service [1]
Pandas provides various built-in methods for reshaping DataFrame. Among them, stack() and unstack() are the 2 most popular methods for restructuring columns and rows (also known as index).
stack(): stack the prescribed level(s) from column to row.unstack(): unstack the prescribed level(s) from row to column. The inverse operation from stack.
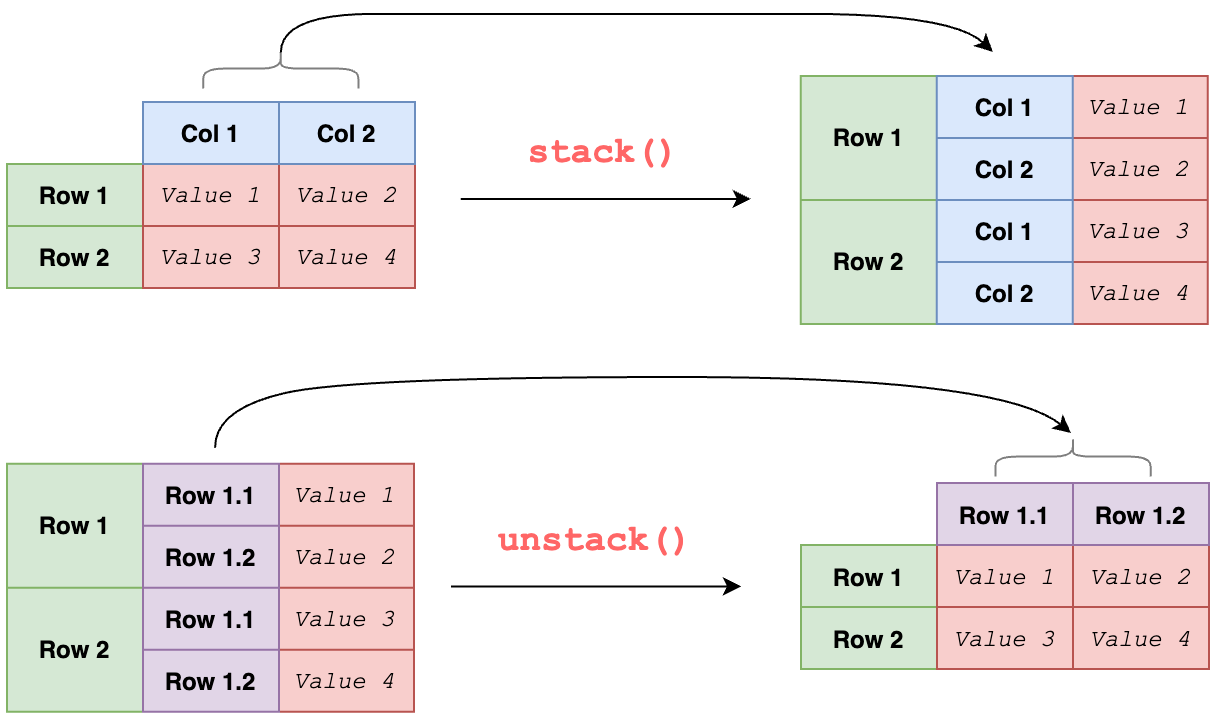
stack() and unstack() seem fairly straightforward to use, but there are still some tricks you should know to speed up your data analysis. In this article, you’ll learn Pandas tricks to deal with the following use cases:
- Single level
- Multiple levels: simple case
- Multiple levels: missing values
- Multiple levels: specify a level to…

